13.3 Autoscaling 테스트
Step #5: 부하 발생에 따라 Instance Pool내에 인스턴스 수 증가 - Scale Out 테스트
-
Instance Pool로 이동해서 현재 있는 Compute 인스턴스의 IP를 확인한 뒤 SSH로 접속합니다.
-
stress 툴 설치
sudo yum-config-manager --enable ol8_developer_EPEL sudo yum install -y stress -
stress 수행
sudo stress --cpu N -
실행 예시
사용할 Compute Instance의 CPU에 갯수에 맞춰 조정하여 부하를 계속 줍니다. 오토스케일 설정시 정한 Cool Down을 값을 고려하여 그 시간 이상 부하를 줍니다.
[opc@web-server-template ~]$ sudo stress --cpu 4 stress: info: [42769] dispatching hogs: 4 cpu, 0 io, 0 vm, 0 hdd
부하발생 중 모니터링
-
OCI 콘솔에서 내비게이션 메뉴를 엽니다. Compute > Instance Pools 항목으로 이동합니다.
-
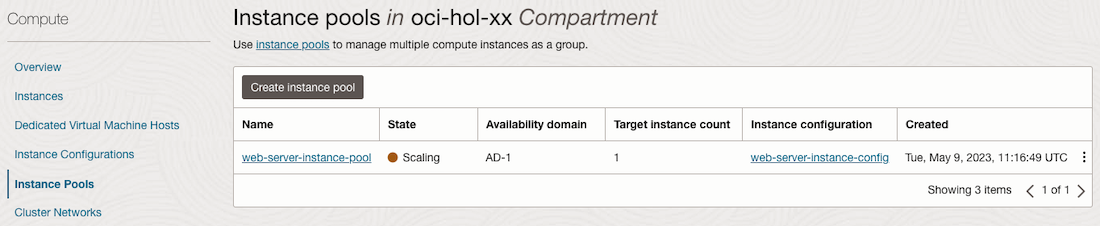
Autoscaling 할 Instance Pool의 상세화면으로 이동합니다.
-
Resources > Metrics 에서 인스턴스 풀에 대한 모니터링을 지원합니다.
-
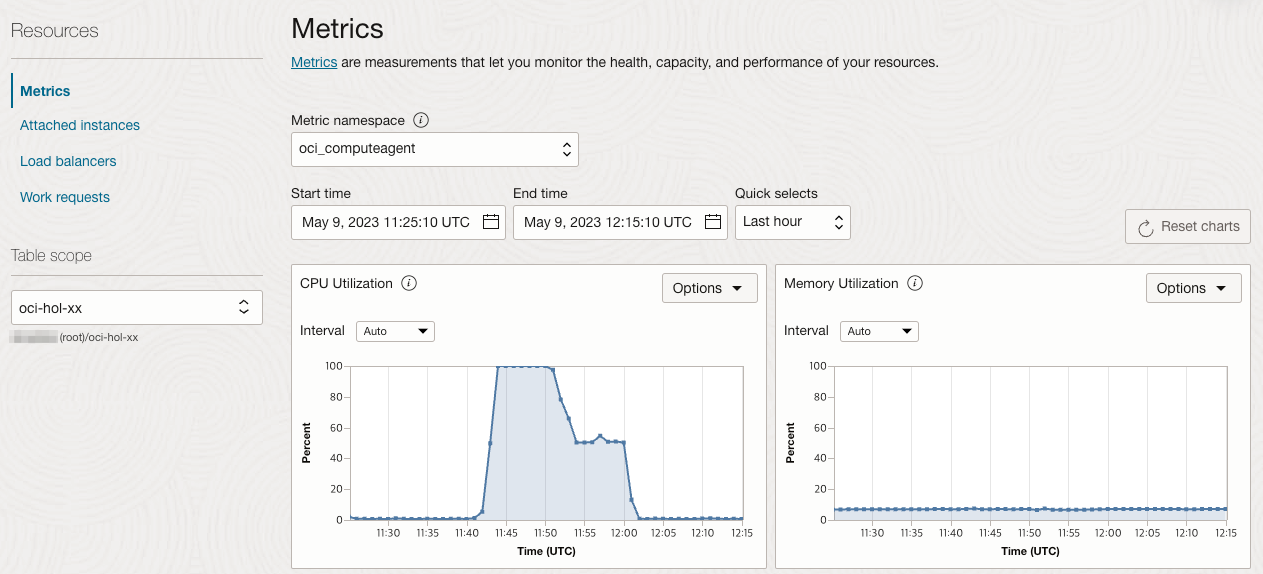
Metric namespace는 oci_computeagent를 선택하면 인스턴스 풀에 속한 VM 들에 대한 메트릭 정보를 볼 수 있습니다. 아래와 같이 CPU 부하가 모니터링 되고 있습니다.
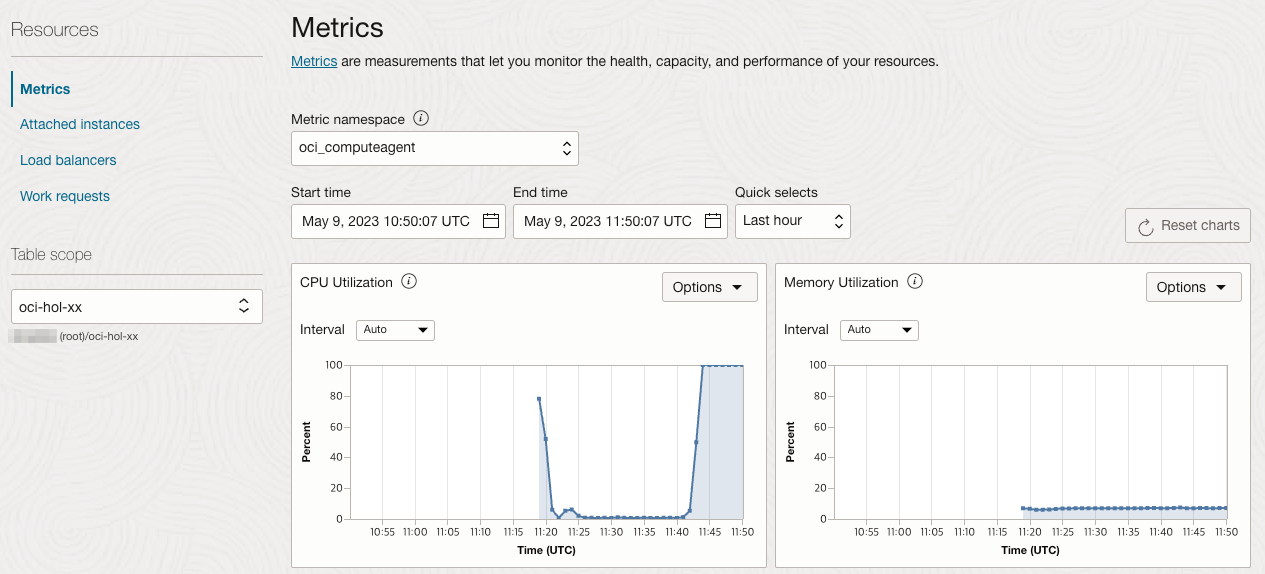
Scale Out 확인
-
지정한 Cooldown을 초과하여 부하가 계속발생하여 그림과 같이 Autoscaling이 발생합니다.

-
Instance Pool 상세 정보에서 서버 추가가 완료된 결과를 볼 수 있습니다.

-
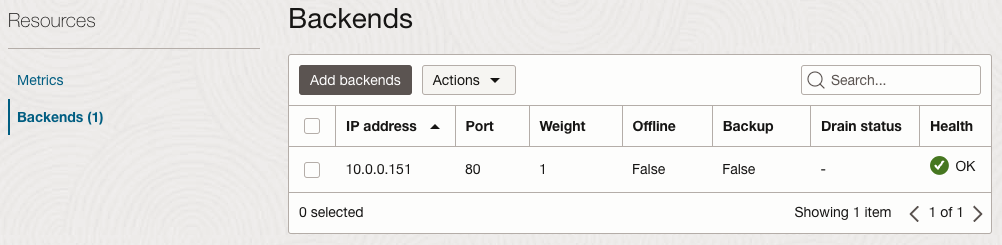
Load Balancer의 Backend Set에서 신규 서버가 추가되는 것을 볼 수 있습니다.
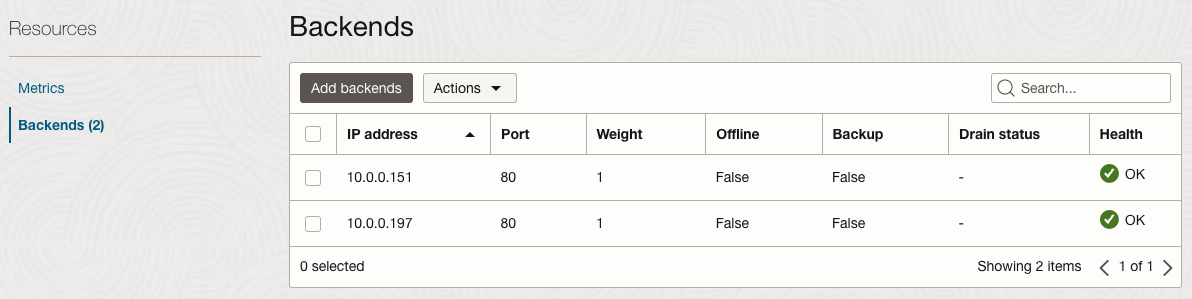
-
서버 추가로 인해 Instance Pool의 평균 CPU 부하는 반으로 내려간 것을 볼 수 있습니다.
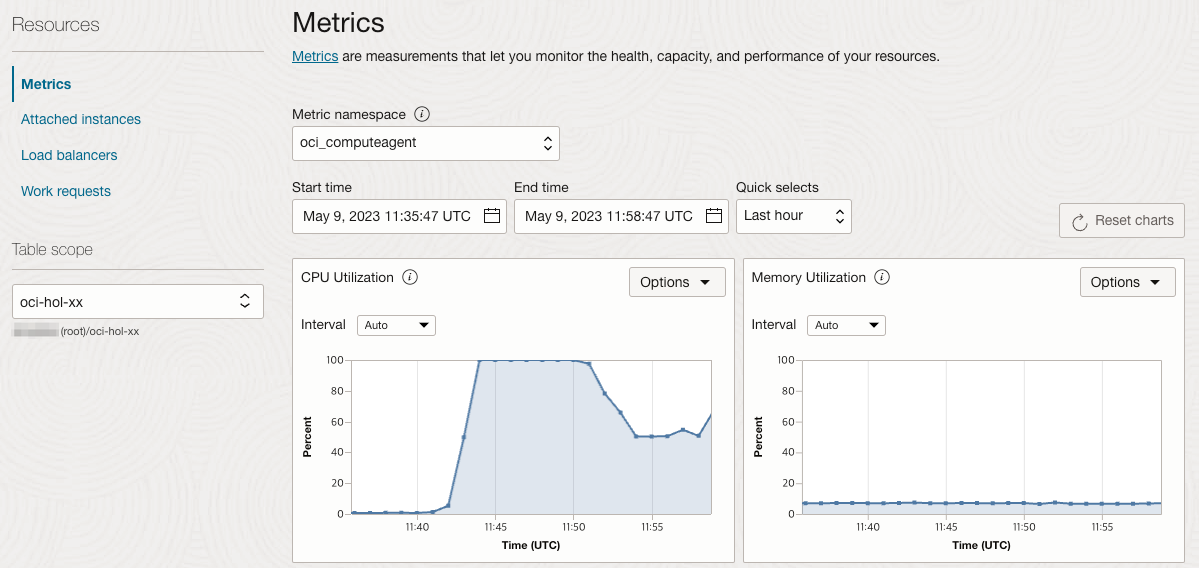
-
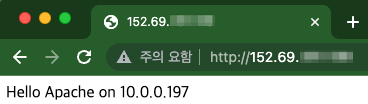
브라우저를 통해 LB의 Public IP로 접속합니다.
-
브라우저를 리프레쉬합니다. 잘 분배되는 것을 볼 수 있습니다.
Step #6: 부하 감소에 따라Instance Pool내에 인스턴스 수 감소 - Scale In 테스트
-
1번 서버 SSH 접속 터미널에서 주던 부하를 중지합니다.
[opc@web-server-template ~]$ sudo stress --cpu 4 stress: info: [42769] dispatching hogs: 4 cpu, 0 io, 0 vm, 0 hdd ^C [opc@web-server-template ~]$ -
모니터링에서 Instance Pool의 평균 CPU 부하가 감소되었습니다.
-
부하가 줄어들어 그림과 같이 Autoscaling이 발생합니다.
-
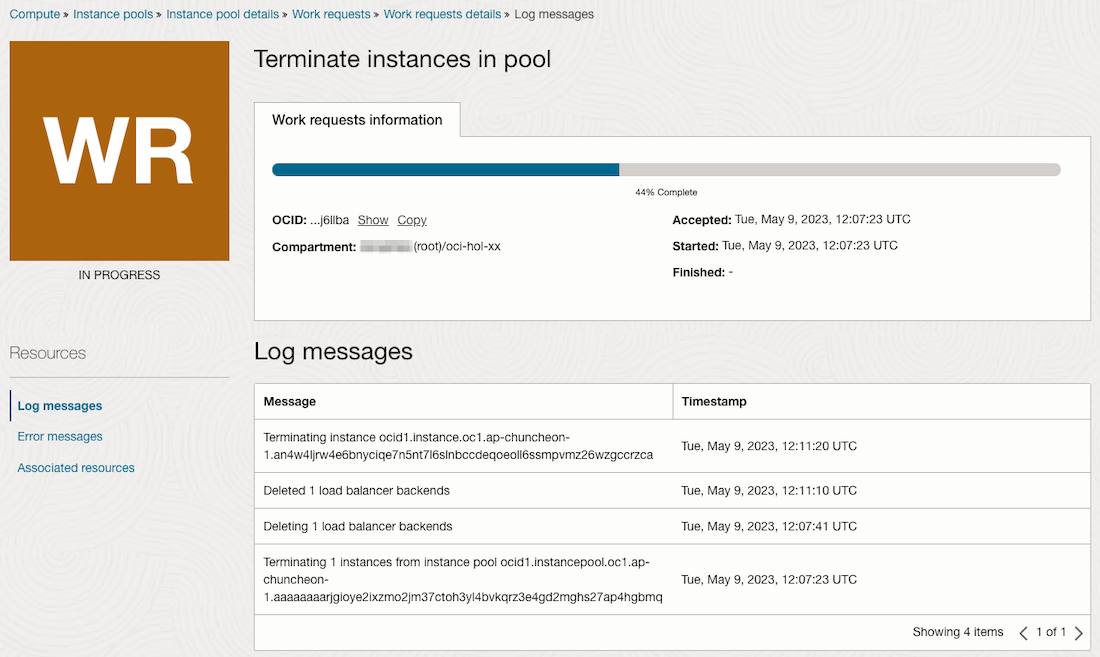
Work Requests 상의 로그를 보면 Load Balancer에서 먼저 인스턴스를 백엔드 셋에서 제외하고 종료하는 순으로 Scale In이 됩니다.
-
Scale In 완료

-
Load Balancer의 Backend Set에서도 삭제된 것이 확인됨.
이 글은 개인으로서, 개인의 시간을 할애하여 작성된 글입니다. 글의 내용에 오류가 있을 수 있으며, 글 속의 의견은 개인적인 의견입니다.