17.1 Kafka Connect, Debezium로 PostgreSQL CDC 구성하기
Kafka에서 Debezium Connector를 통해 데이터 변경분 캡쳐(CDC)를 수행하고, JDBC Connector를 통해 대상 시스템에 동기화는 것을 구현하는 경우가 있습니다. 여기서는 Kafka를 대신하여 Kafka 호환 서비스인 OCI Streaming을 사용할 수 있는 지, 사용시 유의사항이 있는 지를 확인해 보고자 합니다. 그래서 여기서는 Kafka에 대한 자세한 설명보다는 OCI Streaming로 가능 여부 확인에 우선합니다.
Source PostgreSQL -> Debezium Connector -> OCI Streaming -> JDBC Connector -> Target PostgreSQL 구성으로 CDC를 구성하도록 하겠습니다.
Kafka API 지원
OCI Streaming 서비스는 Apache Kafka 호환 서비스로 대부분의 Kafka API와 호환합니다. 지원 Kafka API는 다음과 같습니다. 아래 Kafka API를 지원하기 때문에, 위 Kafka Connect를 이용한 CDC 구성은 가능하다고 판단되어, 아래 테스트를 진행합니다.
- Producer (v0.10.0 and later)
- Consumer (v0.10.0 and later)
- Connect (v0.10.0.0 and later)
- Admin (v0.10.1.0 and later)
- Group Management (v0.10.0 and later)
업데이트 및 정확한 사항은 공식 문서 Using Streaming with Apache Kafka > Kafka API Support를 참조하세요.
필요한 OCI Policy
-
Compute 인스턴스, Container Instance, Streaming을 사용하기 위해 Policy를 사전에 구성합니다.
# Compute Instance Allow group {domain-name}/{group_name} to manage instance-family in compartment {compartment-name} Allow group {domain-name}/{group_name} to use volume-family in compartment {compartment-name} Allow group {domain-name}/{group_name} to manage virtual-network-family in compartment {compartment-name} # Container Instance Allow group {domain-name}/{group_name} to manage compute-container-family in compartment {compartment-name} # OCI Streaming Allow group {domain-name}/{group_name} to manage stream-family in compartment {compartment-name}
Source, Target PostgreSQL 데이터베이스 구성
먼저, Source, Target으로 사용할 PostgreSQL 데이터베이스 인스턴스를 만듭니다. 설치 편의상 debezium에서 제공하는 컨테이너 이미지를 사용하여, OCI Container Instance 서비스로 사용할 환경을 만듭니다.
- 참고 - Source DB에 설정 요구사항
- Debezium Setting up Postgres을 기준으로 설정값을 확인해 봅니다.
- 참고로, 작성일 2024년 5월기준, OCI Database with PostgreSQL 서비스는 아직 Debezium을 지원하지 않는다고 합니다.
Source PostgresSQL 생성 정보
-
OCI 콘솔에 로그인합니다.
-
좌측 상단 햄버거 메뉴에서 Developer Services > Containers & Artifacts > Container Instances 로 이동합니다.
-
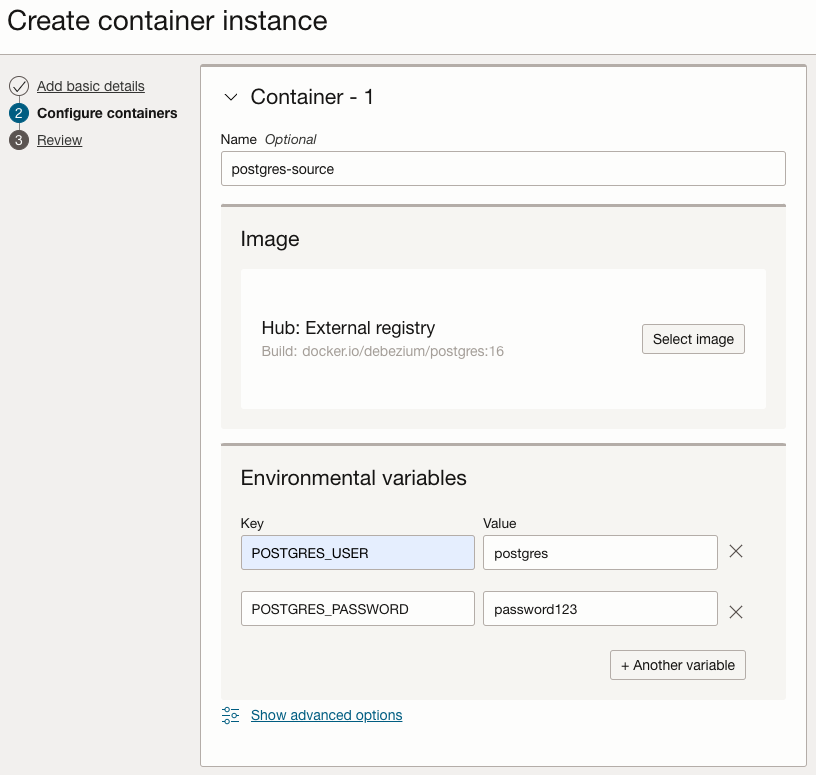
아래 정보로 Container Instance를 생성합니다.
- Name: postgresql-source
- Networking: 편의상 Public Subnet 사용
- 컨테이너 이미지
- Registry hostname:
docker.io - Repository:
debezium/postgres - Tag:
16
- Registry hostname:
- 환경 변수
POSTGRES_USER=postgresPOSTGRES_PASSWORD=password123
-
Security List Ingress 규칙에 5432 포트를 개방합니다.
Target PostgresSQL 생성 정보
- 아래 항목만 달리하여 Container Instance를 하나 더 만듭니다.
- Name: postgresql-target
psql client 설치
PostgreSQL에 접속툴로 psql을 설치합니다.
-
Mac 기준
brew install libpq echo 'export PATH="/opt/homebrew/opt/libpq/bin:$PATH"' >> ~/.zshrc source ~/.zshrc # 확인 psql --version -
Oracle Linux 8
sudo dnf install -y postgresql # 확인 psql --version
Source DB에 CDC 대상 테이블 생성
편의상 여기서는 별도 유저 생성없이 기본 관리자 유저를 사용합니다.
-
데이터베이스 접속
psql -h <Source-PostgreSQL-Public-IP> -p 5432 -d postgres -U postgres -
DATABASE 생성 및 선택
postgres=# CREATE DATABASE sourcedb; CREATE DATABASE postgres=# \c sourcedb psql (10.23, server 16.2 (Debian 16.2-1.pgdg110+2)) WARNING: psql major version 10, server major version 16. Some psql features might not work. You are now connected to database "sourcedb" as user "postgres". sourcedb=# -
샘플 테이블 생성
CREATE TYPE gender AS ENUM('M', 'F'); CREATE TABLE employees ( emp_no INT NOT NULL, birth_date DATE NOT NULL, first_name VARCHAR(14) NOT NULL, last_name VARCHAR(16) NOT NULL, gender gender NULL, hire_date DATE NOT NULL, PRIMARY KEY (emp_no) );
Target DB 구성 설정
편의상 여기서는 별도 유저 생성없이 기본 관리자 유저를 사용합니다.
-
데이터베이스 접속
psql -h <Target-PostgreSQL-Public-IP> -p 5432 -d postgres -U postgres -
DATABASE 생성 및 선택
CREATE DATABASE targetdb; \c targetdb -
샘플 테이블 없음을 확인합니다.
select * from employees;
OCI Streaming 서비스 구성 및 연결 준비
- OCI 콘솔에 로그인합니다.
- 좌측 상단 햄버거 메뉴에서 Analytics & AI > Messaging > Streaming 으로 이동합니다.
- 메뉴에서 Stream Pools 을 클릭합니다.
- 아래 정보로 Stream Pool을 생성합니다.
- Stream Pool Name:
cdc-stream-pool - 고급 옵션
Auto create topics선택
- Stream Pool Name:
- 메뉴에서 Kafka Connect Configurations 을 클릭합니다.
- Kafka Connect를 사용하기 위해 필요한 Kafka Topic 3개를 만들 수 있습니다. 아래 이름으로 생성합니다.
- Kafka Connect Configuration Name:
my-kafka-connect-conf
- Kafka Connect Configuration Name:
- 유저 Auth Token 준비
- 기 발급받은 Auth Token이 없는 경우 My profile > Auth tokens 에서 새 Auth Token을 발급하여 기록해 둡니다.
Kafka Connect 설치 및 구성
Kafka 및 Connector 설치
-
OCI 콘솔에서 Kafka Connect를 설치할 Compute 인스턴스를 하나 생성합니다.
- Name: 예, kafka-connect
- OS: Oracle Linux 8
-
설치한 Compute 인스턴스에 SSH로 접속합니다.
-
Java 17을 설치합니다.
yum list jdk* sudo yum install -y jdk-17.x86_64 -
설치 확인
$ java -version java version "17.0.5" 2022-10-18 LTS Java(TM) SE Runtime Environment (build 17.0.5+9-LTS-191) Java HotSpot(TM) 64-Bit Server VM (build 17.0.5+9-LTS-191, mixed mode, sharing) -
Kafka 최신 버전을 설치합니다.
cd wget https://dlcdn.apache.org/kafka/3.7.0/kafka_2.13-3.7.0.tgz tar xf kafka_2.13-3.7.0.tgz mv kafka_2.13-3.7.0 kafka -
Source DB에 CDC를 위한 Debezium PostgreSQL Connector 2.x 버전을 설치합니다.
mkdir -p ./kafka/plugins wget https://repo1.maven.org/maven2/io/debezium/debezium-connector-postgres/2.6.1.Final/debezium-connector-postgres-2.6.1.Final-plugin.tar.gz tar zxvf debezium-connector-postgres-2.6.1.Final-plugin.tar.gz -C ./kafka/plugins/ -
Target DB 연결을 위한 JDBC Connector를 설치합니다.
wget https://d1i4a15mxbxib1.cloudfront.net/api/plugins/confluentinc/kafka-connect-jdbc/versions/10.7.6/confluentinc-kafka-connect-jdbc-10.7.6.zip unzip confluentinc-kafka-connect-jdbc-10.7.6.zip -d ./kafka/plugins/ -
Connector 설치를 확인합니다.
$ ls ./kafka/plugins/ confluentinc-kafka-connect-jdbc-10.7.6 debezium-connector-postgres
Kafka Connect Properties 설정
Kafka Connect는 Standalone Mode와 Distributed Mode로 실행할 수 있습니다. 여기서는 Distributed Mode 기준으로 설정하겠습니다.
-
설치된 기본 속성 파일을 참고하여, 새 설정파일을 생성합니다.
cat ./kafka/config/connect-distributed.properties -
새 설정파일을 만듭니다.
vi connect-distributed.properties -
다음과 같이 설정합니다.
# connect-distributed.properties bootstrap.servers=cell-1.streaming.${REGION}.oci.oraclecloud.com:9092 group.id=debezium-connect-cluster key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable=true value.converter.schemas.enable=true offset.storage.topic=${CONNECT_HARNESS_OCID}-offset config.storage.topic=${CONNECT_HARNESS_OCID}-config status.storage.topic=${CONNECT_HARNESS_OCID}-status offset.flush.interval.ms=10000 security.protocol=SASL_SSL sasl.mechanism=PLAIN sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="${TENANCY_NAME}/${USER_NAME}/${STREAM_POOL_OCID}" password="${AUTH_TOKEN}"; #producer.buffer.memory=4096 #producer.batch.size=2048 producer.sasl.mechanism=PLAIN producer.security.protocol=SASL_SSL producer.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="${TENANCY_NAME}/${USER_NAME}/${STREAM_POOL_OCID}" password="${AUTH_TOKEN}"; consumer.sasl.mechanism=PLAIN consumer.security.protocol=SASL_SSL consumer.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="${TENANCY_NAME}/${USER_NAME}/${STREAM_POOL_OCID}" password="${AUTH_TOKEN}"; plugin.path=/home/opc/kafka/plugins -
위 항목 중 일부 항목은 실제 값을 확인하여 업데이트합니다.
-
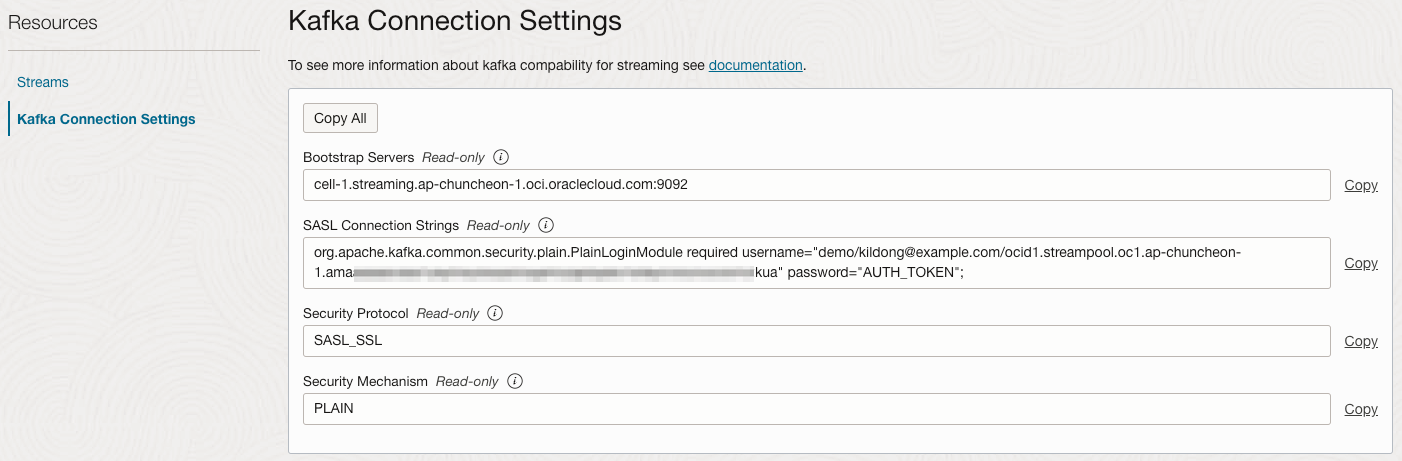
앞서 만든 Stream Pool의 상세 정보에서 Resources > Kafka Connection Settings로 이동합니다.
- bootstrap.servers: Kafka Connection Settings의 Bootstrap Servers 값 사용
- *.sasl.jaas.config: Kafka Connection Settings의 SASL Connection Strings 값에서 AUTH_TOKEN만 변경하여 사용
-
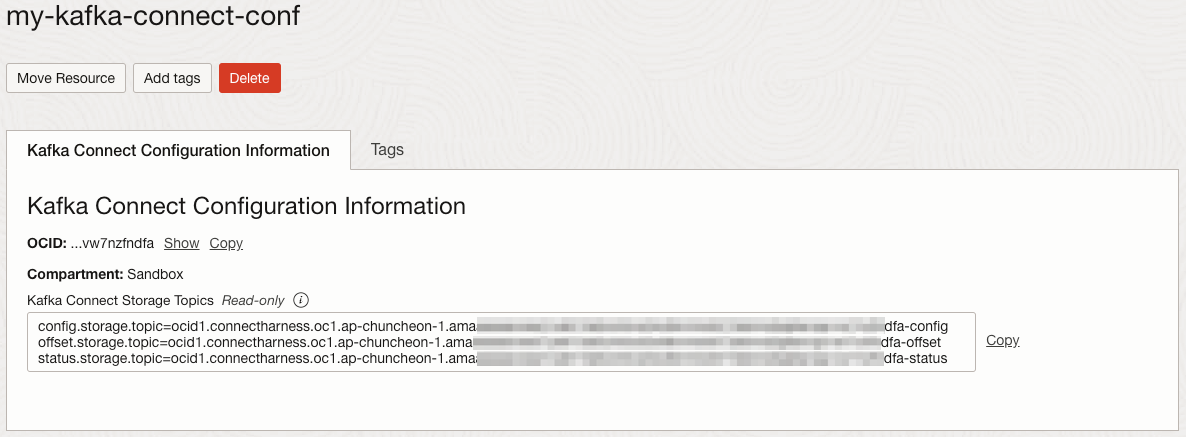
앞서 만든 Kafka Connect Configuration의 상세 정보로 이동합니다.
- offset, config, status.storage.topic: Kafka Connect Storage Topics 값 사용
-
group-id: 필요시 다른 고유한 값으로 변경
-
plugin.path: Debezium, JDBC Connector 설치한 경로 지정
-
Kafka Connect 실행
-
설정 파일을 사용하여 실행합니다.
./kafka/bin/connect-distributed.sh connect-distributed.properties-
실행 결과
$ ./kafka/bin/connect-distributed.sh connect-distributed.properties ... [2024-05-02 09:53:47,998] INFO [Worker clientId=connect-10.0.0.220:8083, groupId=debezium-connect-cluster] Starting connectors and tasks using config offset -1 (org.apache.kafka.connect.runtime.distributed.DistributedHerder:1921) [2024-05-02 09:53:47,998] INFO [Worker clientId=connect-10.0.0.220:8083, groupId=debezium-connect-cluster] Finished starting connectors and tasks (org.apache.kafka.connect.runtime.distributed.DistributedHerder:1950) [2024-05-02 09:53:48,643] INFO [Worker clientId=connect-10.0.0.220:8083, groupId=debezium-connect-cluster] Session key updated (org.apache.kafka.connect.runtime.distributed.DistributedHerder:2442)
-
Source DB 연결을 위한 Debezium Connector 설정
-
Source DB 연결을 위한 설정 파일(connector-source-postgres.json)을 만듭니다.
{ "name": "source-postgres-employees", "config": { "connector.class": "io.debezium.connector.postgresql.PostgresConnector", "database.hostname": "xxx.xx.xx.xxx", "database.port": "5432", "database.user": "postgres", "database.password": "password123", "database.dbname" : "sourcedb", "topic.prefix": "source-postgres", "table.include.list": "public.employees", "key.converter": "org.apache.kafka.connect.json.JsonConverter", "key.converter.schemas.enable": "true", "value.converter": "org.apache.kafka.connect.json.JsonConverter", "value.converter.schemas.enable": "true", "time.precision.mode": "connect" } }- database.hostname: Source DB의 IP
- database.user: DB 접속 유저명
- database.password: 유저 패스워드
- database.dbname : 앞서 CREATE DATABASE 명령으로 만든 Source DB상의 DATABASE 이름
- topic.prefix: OCI Streaming에 만들어질 Topic들의 Prefix
- 예, source-postgres
- employees 테이블의 변경분은 source-postgres.public.employees 이름으로 Topic이 만들어지게 됨
- table.include.list: Source PostrgeSQL의 스키마.테이블명으로, 정규 표현시의 콤마리스트
- time.precision.mode: connect: date/time/datetime 포맷 변환을 위해 필요, 하지 않을 경우, birth_date: ‘1953-09-02’가 Target에서는 -5965처럼될 수 있습니다.
-
설정 파일을 사용해 Source DB를 위한 Connector를 배포합니다.
curl --location --request POST 'http://localhost:8083/connectors' --header 'Content-Type: application/json' --data '@connector-source-postgres.json' -
현재 배포된 Connector를 조회합니다.
curl localhost:8083/connectors | jq -
필요시 삭제후 설정 파일 변경후 다시 배포합니다.
curl --location --request DELETE 'http://localhost:8083/connectors/source-postgres-employees'
Target DB 연결을 위한 JDBC Sink Connector 설정
-
Target DB 연결을 위한 설정 파일(connector-target-postgres.json)을 만듭니다.
{ "name": "target-postgres", "config": { "connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector", "tasks.max": "1", "connection.url": "jdbc:postgresql://xxx.xx.xx.xx:5432/targetdb?currentSchema=public", "connection.user": "postgres", "connection.password": "password123", "table.name.format": "employees", "topics": "source-postgres.public.employees", "auto.create": "true", "auto.evolve": "true", "delete.enabled": "true", "insert.mode": "upsert", "pk.mode": "record_key", "key.converter": "org.apache.kafka.connect.json.JsonConverter", "key.converter.schemas.enable": "true", "value.converter": "org.apache.kafka.connect.json.JsonConverter", "value.converter.schemas.enable": "true", "transforms": "unwrap", "transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState", "transforms.unwrap.drop.tombstones": "false", "transforms.unwrap.delete.handling.mode": "none" } }- connection.url: Target DB 접속을 위한 JDBC URL 입력
- connection.user: DB 접속 유저명
- connection.password: 유저 패스워드
- table.name.format: Target DB에 만들 테이블 이름 형식
- topics: 가져올 Topic의 이름 형식
- auto.create: Target DB에 해당 테이블이 없을 경우, 자동으로 만들지 여부 지정
- auto.evolve: Target DB에 해당 테이블과 스키마가 다를 경우, 자동으로 반영할 지 여부 지넝
- delete.enabled: Target DB에 해당 테이블 삭제 가능 여부 지정
-
설정 파일을 사용해 Target DB를 위한 Connector를 배포합니다.
curl --location --request POST 'http://localhost:8083/connectors' --header 'Content-Type: application/json' --data '@connector-target-postgres.json' -
현재 배포된 Connector를 조회합니다.
curl localhost:8083/connectors | jq -
필요시 삭제후 설정 파일 변경후 다시 배포합니다.
curl --location --request DELETE 'http://localhost:8083/connectors/target-postgres' -
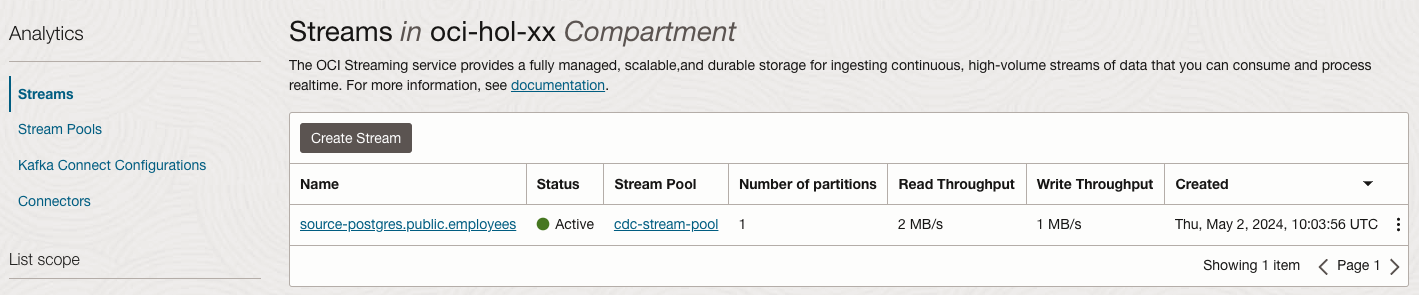
OCI 콘솔에서 Streams 목록을 확인해 보면, 새로 Topic 생성된 것을 확인할 수 있습니다.
CDC 테스트
Source DB에 데이터 변경분 발생
편의상 여기서는 별도 유저 생성없이 기본 관리자 유저를 사용합니다.
-
데이터베이스 접속
psql -h <Soure-PostgreSQL-Public-IP> -p 5432 -d postgres -U postgres -
DATABASE 접속
\c sourcedb -
새 데이터 삽입
INSERT INTO employees VALUES (10001,'1953-09-02','Georgi','Facello','M','1986-06-26'); INSERT INTO employees VALUES (10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21'); -
데이터를 확인합니다.
sourcedb=# select * from employees; emp_no | birth_date | first_name | last_name | gender | hire_date --------+------------+------------+-----------+--------+------------ 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 (2 rows) sourcedb=#
Target DB에 데이터 확인
편의상 여기서는 별도 유저 생성없이 기본 관리자 유저를 사용합니다.
-
데이터베이스 접속
psql -h <Target-PostgreSQL-Public-IP> -p 5432 -d postgres -U postgres -
DATABASE 접속
\c targetdb -
현재 데이터 확인합니다.
targetdb=# select * from employees; emp_no | birth_date | first_name | last_name | gender | hire_date --------+------------+------------+-----------+--------+------------ 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 (2 rows) targetdb=# -
Target DB에 동일 테이블이 생성되고 데이터도 동기화되었습니다.
Kafka Connect 로그 확인
Kafka Connect의 실행로그를 확인하면, 아래와 같이 변경분이 확인하고, Target DB에 테이블이 없음을 확인하고 생성했다는 로그를 확인할 수 있습니다. 또한 2건의 변경분을 전달했다는 메시지도 확인할 수 있습니다.
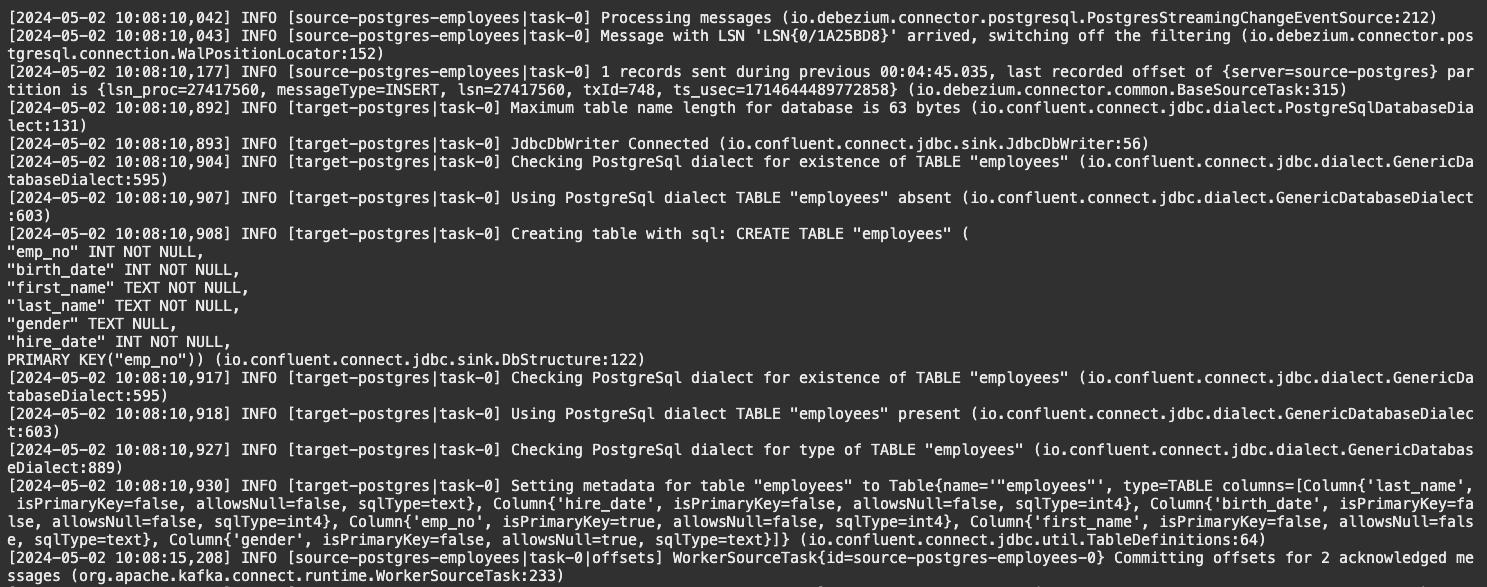
connect-distributed.properties에서 OCI Streaming에서 사용하는 연결방식만 사용하면, 기존 Kafka들 대체하여, Kafka Connect, Connector 플러그인들을 활용하여 CDC를 수행할 수 있는 것을 확인하였습니다.
이 글은 개인으로서, 개인의 시간을 할애하여 작성된 글입니다. 글의 내용에 오류가 있을 수 있으며, 글 속의 의견은 개인적인 의견입니다.